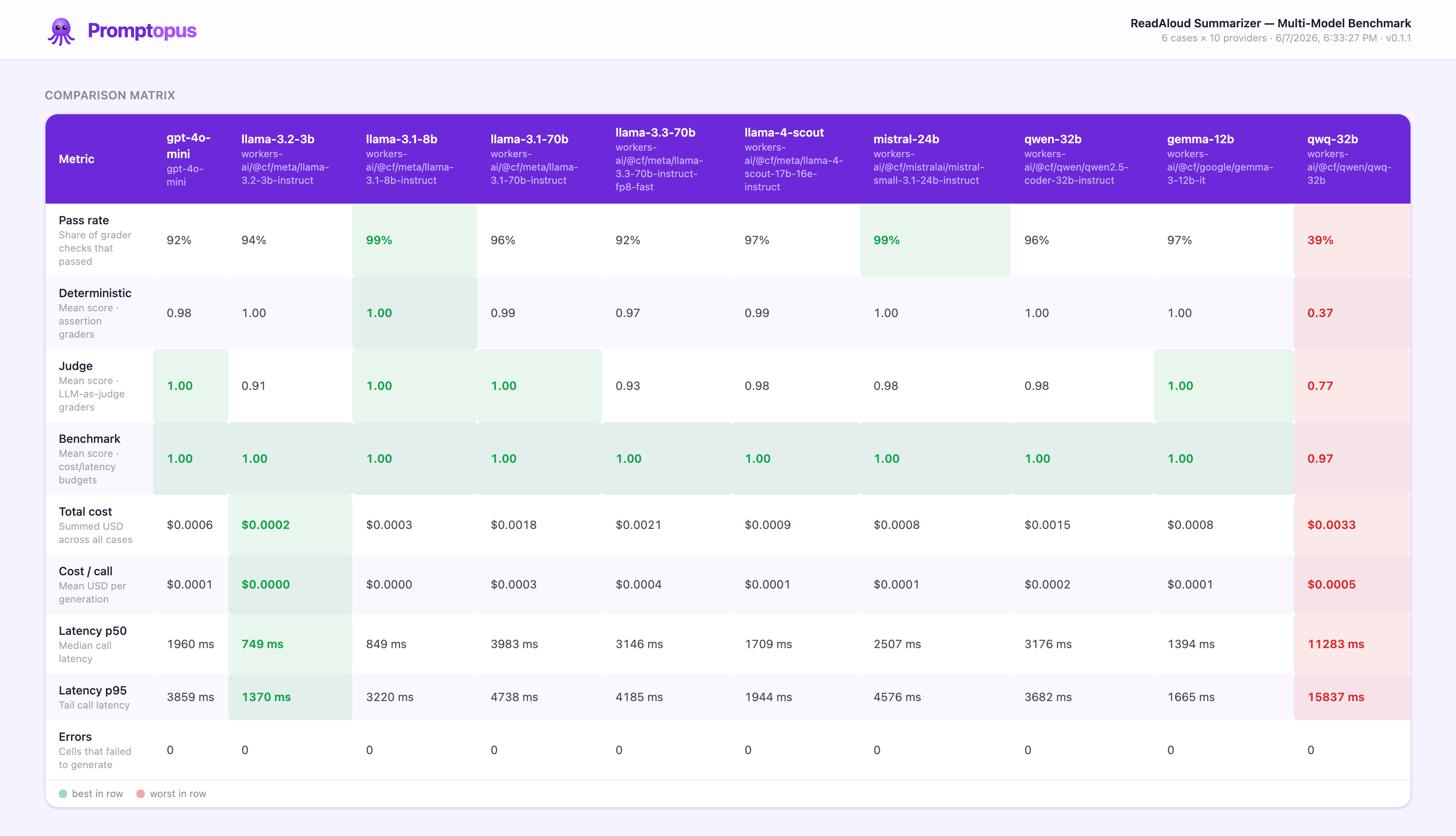
Proven on a real product eval · see the numbers
 ● TypeScript, strict — no
● TypeScript, strict — no
Stop guessing which model to ship.
Promptopus turns "which model, at what cost, at what quality?" into a repeatable, version-controlled experiment. Define an eval in YAML, run it across vendors, and compare models side by side — deterministic checks, an LLM judge, and cost/latency, all in one report.
$ npx promptopus init
any in core ● 52 unit tests ● MIT licensed promptopus run readaloud-summarizer.yaml
🐙 Promptopus — ReadAloud TL;DR Summarizer 5 cases × 2 providers, concurrency 3 [10/10] ✓ coffee-history × llama-8b Metric gpt-4o-mini llama-8b --------------------- ----------- -------- Pass rate 100% 100% Score · judge 0.96 0.99 Cost · total $0.0005 $0.0002 Latency · p95 2436ms 6880ms 🐙 report written to results.json
Runs against OpenAI Anthropic Cloudflare Workers AI Any OpenAI-compatible endpoint Local models